

Det finns huvudsak två sätt för att se till att en sida inte visas eller kan nås från sökmotorers resultat. Beroende på när och hur de implementeras har de lite olika effekt. Här tänkte vi reda ut när och varför du ska använda de olika sätten.
Noindex-taggar
Den vanligaste, enklaste och effektivaste metoden, den som funkar i alla lägen, är att sätta en ”noindex-tagg”. Den kan sättas både som en Meta-tagg eller skickas med i HTTP-headern då den kallas för X-Robots-tagg. Båda två funkar på samma sätt. Så här ser meta-taggen ut i koden:
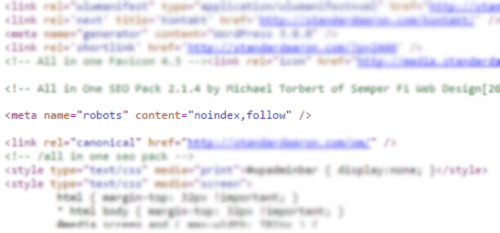
Det en noindex-tagg gör är att säga åt sökmotorns robot att den får läsa sidan, men den ska inte sparas ner i deras index och därmed inte vara sökbar. I de allra flesta fall gör roboten precis så (man kan aldrig lite helt och hållet på robotar, de missar saker ibland). Det här gör att om sidan finns i index innan tas den bort, och om den inte finns där läggs den inte till.
Robots.txt
Det andra sättet är att blockera sidor i en Robots.txt-fil. Det är en fil som berättar för sökmotorerna om de får läsa en sida eller inte. Den säger däremot inget till roboten om den får spara URL:en och sidan i sitt index. Det är det här som är den springande punkten, och nästan alltid anledningen till att en blockerad sida finns kvar i index.
Om Google inte haft sidan indexerad tidigare kommer de i princip alltid helt enkelt strunta i den. De får ju inte besöka den, så de låter den vara. Problemet kommer när de redan har en sida i sitt index. De kommer då vilja besöka den lite då och då för att se om den ändrats. Om den sidan då är blockerad i Robots.txt får de inte besöka den, så de kommer ”ta bort innehållet” ut sitt index, men behålla själva URL:en. De vill ju se om den kommer tillbaka, Googles dröm är att ha all text som någonsin skapats i sitt index, men eftersom de inte vet om det står samma sak där längre poängterar de i sitt sökresultat att sidan är blockerad för dem.
Lösningen
Robots.txt är inte ett dåligt verktyg i sig, men det är ganska trubbigt. Lösningen är att antingen alltid lägga till URL:erna i filen innan de publiceras. Eller ännu hellre, att bara använda ”noindex”, för att vara på den säkra sidan.
