

Vilken typ av fråga som är vanligast att få som SEO-specialist varierar över tid, och det verkar gå i cykler. På sista tiden har jag fått fler och fler frågor som rör bestraffningar av olika slag, och det verkar som att det finns en del begreppsförvirring kring det. Därför ska vi nysta lite i den djungel av filter och straff som är Googles sökresultat. ”Straff” är ganska komplicerade saker när det kommer till SEO och det kan vara svårt att veta exakt vad som hänt och varför.
Två versioner av “samma” sak
Till att börja med finns det två olika mekanismer att ta hänsyn till, där båda två kan ha samma effekt. Det som traditionellt brukar kallas för ”straff” är det Google nu för tiden kallar ”manuella åtgärder”. Det är helt enkelt en människa som tittat antingen på sajten i sin helhet eller en specifik aspekt av sajten, och tagit ett beslut om hur Google vill visa upp den sajten i sina sökresultat. Den andra mekanismen är ”filter”. Olika algoritmer som förändrar vad Google visar i sina sökresultat.
För att förstå vad man kan ha drabbats av, och för att lista ut hur man rättar till det som blivit fel, är det viktigt att förstå hur Google bygger upp sina sökresultat, och hur och när de här två typerna av förändringar påverkar den processen. Förenklat kan man säga att när någon gör en sökning på Google sätts en process igång, där ett stort antal algoritmiska beräkningar görs, för att de ska kunna presentera en så bra lista av resultat som möjligt för den som söker. Här är grunden PageRank, som med hjälp av länkar räknar ut vilken sida som är bäst för just den gjorda sökningen. Ovanpå det läggs en massa andra aspekter, för att förfina “grundresultatet”. Språklig relevans räknas ut, hastighet på sajten, längd på text, antal sidor och så vidare. Google frågar sig om det är en sökning med lokal anknytning så att de borde ha med en karta. Eller om det kanske finns ett nyhetsvärde och de vore bra med en “News box”. Bilder? Knowledge Graph? Listan fortsätter och varje beräkning kan förändra resultatet. Först nu, när det finns ett färdigt sökresultat, läggs filtren på. Det är lite viktigt att komma ihåg, att det är sökresultatet i sig som filtreras, inte sajten eller sidan. Manuella åtgärder däremot kan appliceras under hela den här processen, beroende på vilken typ av åtgärd som gjorts. Oftast läggs även de på i slutet av uträkningarna.
Google talar själva i princip aldrig om straff, de talar om manuella åtgärder eller så pratar de helt enkelt om att algoritmen valt att ranka din sajt lägre.
Vad är ett filter i Googles sökresultat
Filter är en av de områden många, även bland dem som arbetar professionellt, inom SEO missuppfattar. Filter skapar problematik för många eftersom de ofta fungerar helt annorlunda än algoritmen i stort. Nu är det dessutom luddigare.
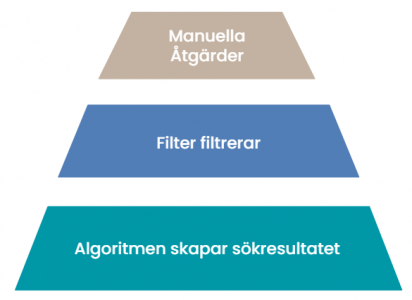
En bild som brukar underlätta att tänka på filter är en pyramid. I botten skapar den vanliga algoritmen sökresultaten, det är den breda grunden alla sökresultat står på. När det väl är gjort går filter igenom sökresultaten och filtrerar bort det som inte borde hamnat där. Ovanpå, på toppen, kommer manuella åtgärder (Manual Action) av Googles team för sökkvalitet. Oavsett vad algoritmen gjort kan filter plocka bort, eller lyfta fram, sajter och oavsett vad båda dessa instanser tycker kan Googles medarbetare rensa bort sajter.
Det fungerar inte riktigt så men det är en bra bild. Under perioder har man dessutom fått veta när filter körs, så det har varit tydligt vad som händer. Vi ska prata specifikt om Panda och Penguin som är de två mest välkända filter Google kört. De har massor med övriga som kommit och gått under åren men dessa är stora och har påverkat brett. Båda är idag en ständig del av algoritmen men under en period kördes de separat, med några veckors eller månaders mellanrum.
Det hände när Panda kördes

Panda är ett filter som agerar mot tunt innehåll. Tunt innehåll är tyvärr en ganska tunn definition men tänk sajter som rankar på massor av sökord utan att egentligen tillföra något. Ehow är kanske det mest kända exemplet med How To-guider på allt från hur man kysser till hur man dricker mjölk. Guiderna är skrivna i en hast just för att snabbt skapa landningssidor, varje sida kan generera några småslantar per månad i Adsenseklick och för att få lönsamhet i det så blir det ganska tunt innehåll som produceras.
För den som inte vet är det Googles filter för att sortera bort svagt innehåll och det första självlärande filter Google lanserade (lite mer läsning om de båda filtren här). Vi tar steg för steg vad som händer:
- Du gör en sökning
- Algoritmen går igenom datan och skapar ett sökresultat för den fras eller det ord du sökt efter. Om man har en sida som kan indexeras ordentligt och som tydligt handlar om ämnet och har tillräcklig auktoritet så kommer man kunna synas.
- Det körs ett filter ovanpå sökresultatet, i det här fallet Panda, som specifikt letar efter sidor som mer eller mindre är massproducerade. Dessa utesluts.
- Det görs också en kontroll om någon på Googles kvalitets-team flaggat innehåll, då utesluts det också ur sökresultatet.
- Det görs personliga, geografiska och lite andra anpassningar för just dig och sökresultatet presenteras.
Anledningen att Panda kom till (och senare Penguin som gjorde liknande saker fast på länknivå) var att man ansåg att sökresultaten fylldes av tunt innehåll. Stora sajter som Ehow skapade miljontals artiklar, med tveksam kvalitet, just för att synas på så många sökresultat som möjligt. I Ehows fall använde man sig av mycket billiga content writers som fick betalt baserad på hur många besökare artikeln fick och styrning för vilka sökord man skulle skriva artiklar för. Det ledde till mycket snabbt hoprafsade artiklar men med rätt rubrik och titel. I kombination med en mycket stark länkprofil kunde man ta förstaplats på söktermer som ”Hur man dricker mjölk” mycket lätt. Det är inte så många sökningar på den termen men om du tänker dig hundra miljoner sådana termer.
En annan variant var innehåll som helt enkelt var data skuret på olika håll. Tänk tanken att du har två recept, ett på Wienerbröd och ett på källarfranska. Du lägger dem i kategorierna Matbröd och Fikabröd och börjar synas bra på de sökorden. För att få lite mer fart lägger du in båda även i ”Bröd som innehåller Vetemjöl” och ”Bakning” och du börjar synas på dessa också. Du inser snabbt att kategorin ”Bröd som innehåller smör” också är smart och snart lägger du till fler och fler kategorier i vilka du bara sorterar dessa två recept. Varje gång du lägger till en ny kategori börjar du synas på ännu ett sökord. Det här går jättebra till dess att Panda-filtret får nog och kastar ut dig ur sökresultatet (och då räcker det inte bara att backa tillbaka till punkten alldeles innan utan du behöver bygga om din sajt till dess Google och Panda anser den tillföra värde).
Det finns saker filtren inte klarar av att hitta men som Google ändå hatar
Nästa steg är sidor som klarat sig väl både när algoritmen bygger sökresultatet och när filtren körs. Ibland slinker det igenom sådant som Google hatar och då görs en manuell åtgärd. Till exempel vuxet innehåll i sökresultat som inte tydligt bör innehålla sådant. Man tycker illa om det på den nivån att Matt Cutts, den första Head of Webspam Google hade, delade ut hembakta kakor till alla som kunde hitta det i något av sökresultaten.
Ett exempel på manuell åtgärd vi sett är ”Ads Above The fold”. Det finns system för att automatiskt rensa bort sidor som verkar gjorda enbart för att visa annonser men ibland misslyckas Google med det om det inte är tydligt att det är annonser. Ett exempel är en topplista med de tio bästa dammsugarna, där du får betalt för trafik du driver till dammsugarförsäljarna eller vilken försäljning du genererar åt dem. Det är inte alltid tydligt för Google att det här är fråga om annonser men det är något de vill undvika att visa, om inte sidan tillför väldigt mycket i övrigt i form av recensioner och liknande.
Vi har, som nämnt, sett ett exempel när detta manuellt rensats bort ur sökresultatet och Google är då så pass trevliga att de meddelar detta i Search Console. Man får ett meddelande om vad (på ett relativt luddigt sätt) de anser man brutit mot och att de vidtagit åtgärd. Många brukar kalla det här att man blir ”straffad” av Google men Google själva vill inte kalla det straff utan helt enkelt en manuell åtgärd. Om det skulle inträffa behöver man åtgärda problemet och skicka in en reconsideration request, beskriva vad man rättat till och hoppas att den som läser det gillar det man gjort.
Det går alltså att med sämre metoder, footerlänkar är ett aktuellt exempel, tillfälligt ta positioner men för att i ett senare skede falla som en sten. En erfaren sökmotoroptimerare vet detta och man kan mycket väl anse att det är en risk värd att ta. Att tillfälligt hålla positioner på ett sökord man inte annars har möjlighet att ta kan mycket väl vara en lönsam strategi. Det gäller att veta vad man gör däremot och för det krävs erfarenhet
Vad är Penguin, Googles andra kända filter

Om du läst på om sökmotoroptimering de senaste åren är du säkert bekant med Pingvinen. Der är, precis som Panda, ett filter som appliceras på sökresultaten och filtrerar bort sajter som inte lever upp till filtrens krav. När det gäller Panda så filtreras sajter med ”tunt innehåll”. Penguin kan sägas gå mot ”tunna länkprofiler” på samma sätt.
Det pingvinen gör är att filtrera sajter som rankar bättre än de borde, inte på grund av att de skapat landningssidor med tunt innehåll utan att de har länkar som inte har den fyllighet som behövs. Eftersom länkar är en bristvara inom all sökmotoroptimering har många försökt kräma ur maximalt resultat ur de länkar de haft. Framför allt handlar det om ankartextfördelning. Att ha en länk med ankartexten Billiga Bilar ger en klar fördel på sökfrasen billiga bilar, då är det lätt att lockas att allt för ofta länka med just den ankartexten. Det har tidigare varit ett mindre riskfyllt förfarande än det är idag, även om det tidigare också funnits filter så har de inte varit aggressiva på samma sätt som penguin.
Det som många lidit extra av det senaste året är att om du blir filtrerad av pingvinen kan du inte komma tillbaka till dina tidigare resultat innan datan i pingvinen uppdateras. Tidigare har det gjorts med månaders mellanrum, det senaste året har de som råkat trampa fel fått vara borta från sökresultaten i princip i ett helt år. Oavsett om de rättat till problemen eller inte. Vad ska du göra om du fastnat i filtret då?
Det här behöver du göra för att komma ur Penguin
Det penguin handlar om är alltså länkar och om du kunnat dra slutsatsen att det faktiskt är penguin som drabbat din sajt är det där du ska lägga fokus. Ibland kan det vara svårt att veta exakt vad som hänt med en sajt, se först till att vara säker på att det är penguin och inte panda eller något annat filter.
Du behöver rensa bort länkar
Du behöver rensa länkar i två steg, det första är att du behöver kontakta alla som länkar till dig på ett för aggressivt sätt och be dem ta bort länkarna eller sätta nofollow-attribut på dem. Det här är förstås ett stort jobb om sajten har gott om länkar in men det behöver göras.
Nästa steg är att med hjälp av Googles verktyg för disavow be Google ignorera de länkar som inte gått att få bort. Åtminstone tidigare har det varit viktigt att inte bara förlita sig på disavow, det är inte 100% säkert att det fortfarande är så.
De länkar du behöver hitta och eliminera är länkar med följande egenskaper:
- Länkar med kommersiella sökord i ankartexten, ju mer ankartexten exakt matchar sökfrasen desto viktigare.
- Sitewide-länkar, länkar från alla sidor på en sajt, ju fler sidor från en sajt som länkar desto viktigare.
- Länkar med sämre placering på sidan. Länkar i löpande text är minst riskabla, länkar i footer mest och däremellan sorterar övriga placeringar in sig. Ta i första hand bort de länkar som ser mest orimliga ut att någon klickar på som tumregel.
- Det är viktigt att i det här läget vara ganska tuff mot sin länkprofil, även sådant som du tycker klarar sig över gränsen behöver tas bort, du måste skära hårt. Anledningen är att du inte kan ta lite i taget och Google är rätt så stränga när du väl fastnat i pingvinen. När de väl kör uppdateringen av datan vill du veta att du kommer tillbaka hellre än att vänta ett halvår eller kanske till och med ett år ytterligare.
Panda och Penguin kanske inte är så farliga längre
Det började som en känsla men efter att ha pratat igenom det med många av de större spelarna i branschen är jag allt mer säker. Panda och pingvin har blivit mjukare. Den senaste Pingvinuppdateringen passerade mer eller mindre obemärkt och knappt någon skälver när de hör ordet panda längre. De lanserades med buller och bång men när de nu visar sina respektive trynen i SEO-världen är det knappt någon som blir nervös.
Det finns två teorier kring fenomenet. Den första är att SEO-samhället nu blivit bättre på att hantera både panda och pingvin. När panda dök upp för första gången och sajter som Reco.se och många andra som baserade sig på svenska företagsregistret störtdök i resultaten trodde många att det var kört för SEO. Så var det förstås inte och SEO-världen anpassade sig. Nu har vi som gör SEO blivit så pass duktiga på att hantera pandan att haverier i stil med Reco.se har försvunnit.
Den andra teorin är att Google faktiskt minskat effekten av de båda filtren. Kanske för att de upplevde att resultaten faktiskt inte blev bättre eller på grund av de många ”falska positiva” svar de fick, att så många blev filtrerade som inte förtjänade det. Min personliga åsikt är att båda är sanna, ingen seriös sökmotoroptimerare skulle indexera sökresultat idag och Google har blivit lite snällare. Content farms i stil med Reco.se är inte längre ett problem för Google så därför har de skruvat ner effekten av Panda. På samma sätt behövs inte pingvinen lika mycket och därför har de lugnat sig med den.
Pingvin och Panda är idag införlivade i algoritmen och rullar på ett mer förutsägbart sätt, dessutom har man värderat om så att dåliga länkar, till exempel, inte väger negativt i pingvinen utan istället bara inte räknas. Google vill själva mena att man är relativt bra på det.
Filter för Pop Ups
Google har sedan länge varit emot allt för mycket reklam på sidor. Sidor där en större del av innehållet döljs bakom en pop up (inte samtliga pop ups, om det handlar om till exempel en ålderskontroll på sajter där det krävs av lagliga skäl ska filtret inte appliceras) kommer få sämre positioner i ett försök att göra sin sökmotor bättre för mobilanvändare. Det går att anta att det heller inte applicerar på Cookie-pop ups.
Några exempel på pop ups Google tar upp som stör användarupplevelsen för mobilanvändare är annonser som döljer övrigt innehåll, pop ups man måste klicka bort för att nå innehållet och när man pressar undan det egentliga innehållet.
Man menar på Google att man sedan ett antal år helt enkelt försämrat sökresultaten för dessa, vi är mer tveksamma till att så är fallet.
Problemet med att ha lärt sig en taktik snarare än att förstå
Allt för ofta sitter sökmotoroptimerare, både amatörer och proffs, fast i en taktik. Man har lärt sig en taktik för att göra sökmotoroptimering snarare än att förstå sökmotorn. Vi ser det här hela tiden. Särskilt när det gäller att lägga till sidor för att synas på en sajt. Stora svenska E-handlare som forcerar fram nya kategorier på löpande band för det ger bra resultat på kort sikt. SEO-specialisten de använder sig av har lärt sig att om man lägger till en kategori för ”Bröd som innehåller smör” och på den sätter rätt titel och rubrik så kommer man börja synas på sökningar som har med smör och bröd att göra. Problemet är att om man använder den taktiken hela tiden så kommer man efter ett tag till situationen där Google helt tappar förtroendet för sajten och man försvinner ur ALLA sökresultat.
Om du har 6 eller 12 månaders erfarenhet av sökmotoroptimering så har du helt enkelt aldrig sett ett filter. Du kanske har köpt dig en sökordsdomän, installerat WordPress med Yoast och dunkat länkar på den till dess du syns och vips tror du att du är en expert på SEO. Det är inget fel på varken WordPress, Yoast eller länkar men det är en fråga om tidshorisont.
Jag har vid ett tillfälle tagit förstaplatser i USA på högkonkurrenssökord med en sajt med fem slarvigt skrivna sidor och footerlänkar från 2.4 miljoner ryska sajter (till en total kostnad av 500 dollar). Det är en taktik som fungerar, och den fungerade jättebra de fem dagarna sajten alls fanns i Googles index.
Vad är en manuell åtgärd?

Googles manuella åtgärder har två huvudsakliga funktioner. Den första är att “akut” plocka bort en sajt eller sida från sökresultat där de inte vill visa den, men där algoritmen och filtren inte räcker till för att bedöma det. Det här kan göras på olika sätt. Exempelvis kan det innebära att Google slutar spindla sajten och tar bort den från det index algoritmen har att välja sajter från. Man kommer alltså inte ens med och får tävla när någon gör en sökning. Det kan också innebära att en, några eller alla länkar ges ett negativt värde, vilket gör att landar längre ner i listan när PageRank-algoritmen körs, och därmed har svårare att få en bra position när den listan sedan förfinas. I vissa fall fungerar även manuella åtgärder på samma sätt som filter, och appliceras i slutet av beräkningarna, man kan till exempel flyttas ner 10 positioner eller alltid behöva ligga allra sist i den 1 000 resultat långa listan. Den andra funktionen de här åtgärderna har är att samla in data för att kunna bygga nya eller förbättra befintliga algoritmer och filter. Alla (eller i alla fall de flesta) manuella åtgärder får man reda på genom att installera Google Search Console på sin sajt. Då får man ett meddelande där om att en manuell åtgärd har tagits mot sajten och en kort förklaring varför. Det kan handla om allt från dåliga länkar via dåliga texter till för mycket annonser på sidor. Då är det bara att sätta sig och försöka förbättra det de tagit upp där, och när man anser sig vara klar skickar man ett meddelande till Google där man berättar vad man gjort, att man är ledsen och att man inte tänker göra om det. Är de nöjda med det tas åtgärden bort.
Vad är skillnaden mellan en manuell åtgärd och ett filter?
Faktiskt inte så mycket. Den stora skillnaden är snarare att de finns på områden där Google anser sig ha tillräckligt med data för att kunna låta en dator ta besluten istället för en människa och att de som sagt alltid appliceras när sökresultaten redan är byggda. Det som skiljer sig är hur man gör för att sluta bli bortfiltrerad. Filter är i princip en regel för en viss sak, ett gränsvärde som man ska hålla sig över eller under. Väldigt förenklat handlar det alltså om att hålla sig på rätt sida om varje sådant värde. Så länge man gör det är allt okej. Om man går förbi ett värde blir man bortfiltrerad och när man kommer tillbaka på rätt sida (och över en tröskel) släpps sajten igenom igen. Nu är det inte riktigt så enkelt. Gränsvärdena är inte alltid statiska. De kan ändras över tid, och Google berättar inte vilka filter de har eller var gränserna går. Inte rakt ut i alla fall. En annan aspekt som försvårar är att vissa filter “alltid” körs baserat på det index Google har medan andra uppdateras mer eller mindre regelbundet.
Vilka kan bli ”straffade” av Google?
Ibland fastnar man i ett filter eller manuell åtgärd för att man aktivt tagit en medveten risk. Ibland hamnar man där för aggressiv SEO. Allt som oftast hamnar man i filter eller får en manuell åtgärd för att man helt enkelt inte kände till att det var något som kunde hända. Ett tydligt exempel på det är de många gånger Google straffat sig själva. 2012 till exempel när Google Chrome (som då var nytt) hindrades från att ranka i sökresultaten.
Ett exempel på Manuell Åtgärd med en liten bismak
Är det möjligt för en sajt att komma tillbaka till sökresultaten dagar efter att Google gjort en manuell åtgärd mot den? Thumbtack lyckades på 6 dagar efter att sajten inte ens kunde hittas på sitt eget namn. Kan det ha med ägarna att göra?
Thumbtack fick 2015 en manuell åtgärd och syntes under en kort period inte ens på sitt eget namn i sökresultaten. Att komma ur en manuell åtgärd är ofta ett segdraget jobb och det handlar vanligtvis om väldigt mycket arbete och inskickade ”reconsideration requests” till Google som vanligtvis tar månader på sig att besvara och mer ofta än inte behöver man göra om hela förfarandet ett antal gånger. Det gick förstås en hel del rykten i SEO-världen när det här hände, för att Google var huvudägare till företaget.
För det första behöver du få åtgärden lyft, det i sig tar någon eller några veckor. Du måste först åtgärda felet, i det här specifika fallet få bort så många av länkarna som möjligt och ladda upp en disavow. Sedan behöver du formulera det här i en reconsideration request och om du lyckats kräla i stoftet tillräckligt kommer Googles kvalitetsgranskare släppa sin bannbulla. Då är du i sitsen att du har rensat bort en ansenlig andel av dina länkar och du kommer inte alls kunna hålla positioner som i dina fornstora dar. Man kommer helt enkelt inte tillbaka till fullo från en länkbaserad åtgärd. Om det är en åtgärd av det mycket vanligare slaget, felaktigheter på sajten, är det en annan sak. Om du till exempel har för mycket ”ads above the fold” är det inte så svårt att lösa snabbt och smidigt.
För Thumbtack verkar situationen vara en annan. 6 dagar efter att de blev utkastade ur resultaten är de nu tillbaka starkare än någonsin.
Nog är det hedervärt att Google faktiskt väljer att göra en manuell åtgärd mot sajter de själva äger men den här historien berättar ett antal hemligheter. Den första att om inte det bloggats om deras länkbygge så hade det knappast agerats mot det, åtminstone inte just nu. Den andra att om man fått en investering av Google så blir man visserligen, tillfälligt, behandlad precis som alla andra men det verkar inte allt för svårt att bli på god fot med sökjätten igen. Den tredje och kanske mest cyniska slutsatsen är att nog vill Google premiera sina egna sajter i sökresultaten, frågan är bara hur mycket de törs innan domstolarna slår till.
